Introduction to Causal Inference
Causal Inference and Digital Causality Lab
Welcome!
About the Digital Causality Lab
- Digital Causality Lab (1 SWS, Oliver Schacht)
- New - replaces the former tutorial
- Focus on practice, implementation and tools
- Data Literacy skills
- Independent learning and collaboration
- Teaching Phase and Data Product Phase
- Wednesday, 2 pm and 3 pm, WiWi 2079
- Questions to oliver.schacht@uni-hamburg.de
Welcome!
1. Teaching Phase
Notebooks available from the DCL website
Introductory videos on Lecture2Go (link available in STiNE)
Q & A in in-person meetings with Oliver
Welcome!
1. Teaching Phase
Topics and Tools
- Recap: Statistics
- Introduction to R
- Introduction to GitHub and Git
- R for Causal Inference
- Data Products with Quarto
Welcome!
2. Data Product Phase
- Independent development of a data product on causality
- Solve case study in a group of students
- Choose a topic that you find interesting!
- Creative solution: It’s all up to you, from the concept to the implementation
- Three milestones (concept, midterm, final)
- From week 3/4 on
Welcome!
2. Data Product Phase
- Case Study Topics
- Illustration of causal phenomena
- Graphical approaches
- Real-data examples
- Illustration of estimation approaches
- Causal estimation in practice
- List of potential topics for case studies available here
Welcome!
About the DCL
- How to make the most out of the DCL
- Prepare the first lab sessions: Videos and notebooks
- Be there and participate actively
- Ask questions
- Collaborate with your colleagues and help others
- Be creative
Always keep your head up: Don’t get frutstrated too easily
Outlook
Plan for the course
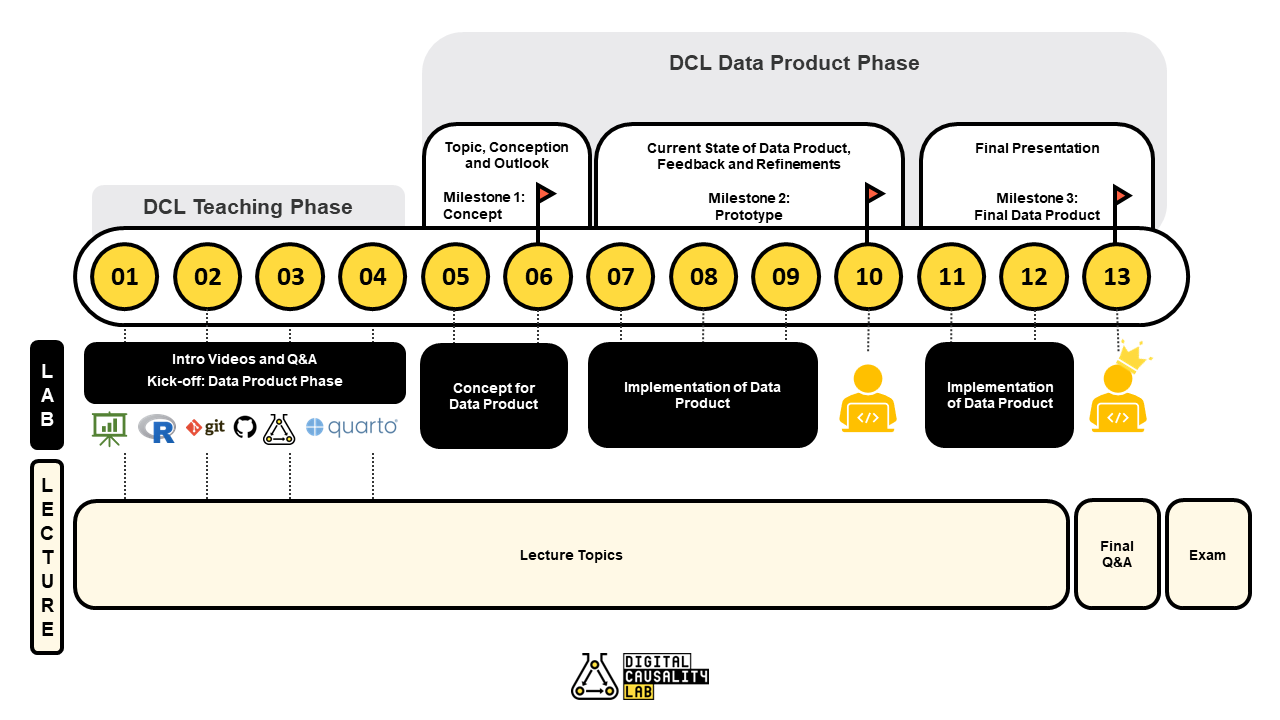
Motivating Examples
Correlation vs. causation
We must learn to analyze data and assess causal claims — a skill that is increasingly important for business and government leaders.

Source: https://hbr.org/2021/11/leaders-stop-confusing-correlation-with-causation
Motivating Examples
Simpson’s paradox: does more exercise lead to higher cholesterol?
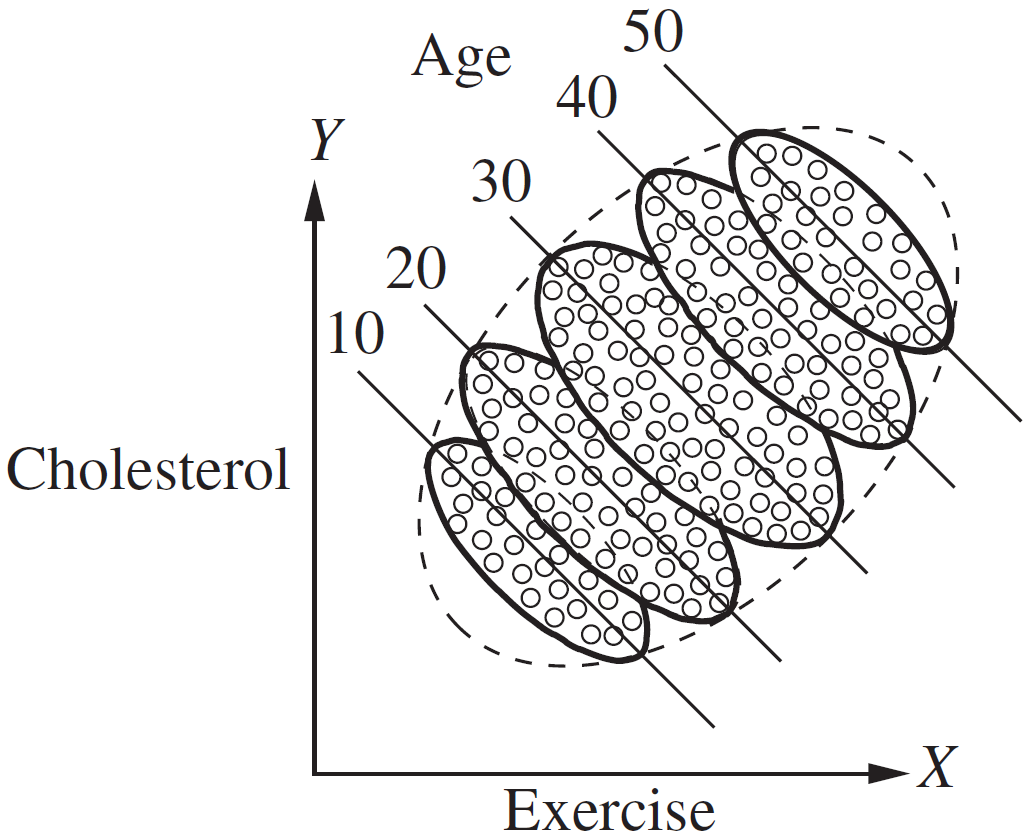
Figure 1.1 Results of the exercise–cholesterol study, segregated by age
Source: Glymour, Pearl, and Jewell (2016)
Motivating Examples
Simpson’s paradox: does more exercise lead to higher cholesterol?
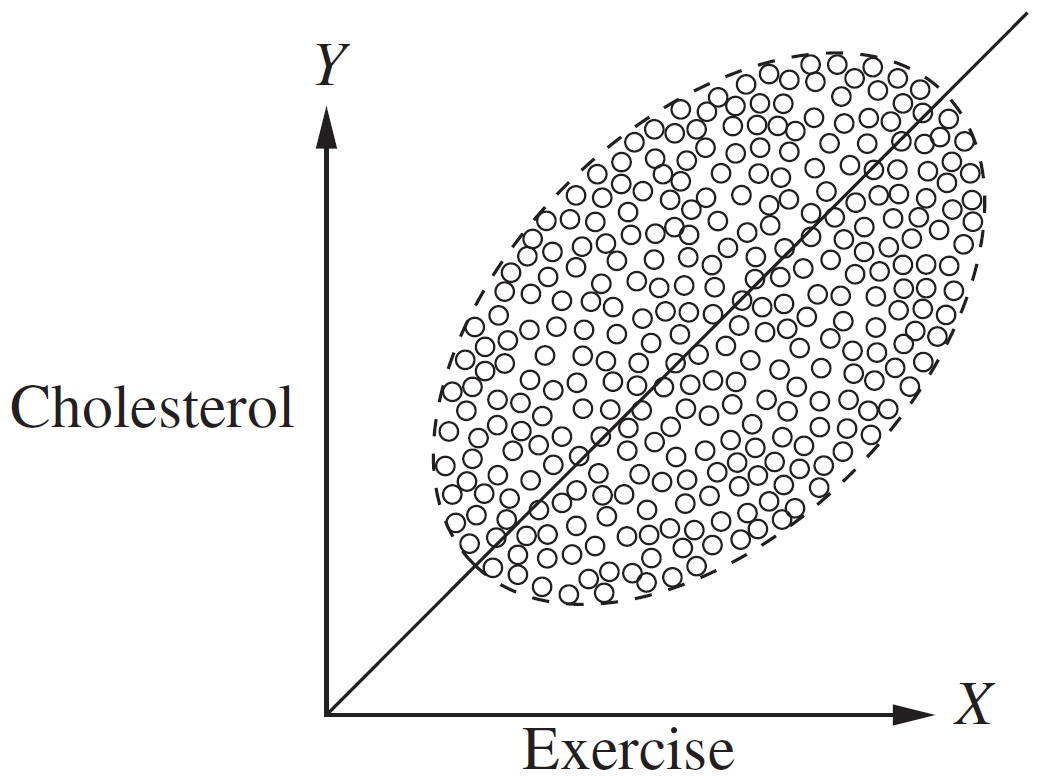
Figure 1.2 Results of the exercise–cholesterol study, unsegregated. The data points are identical to those of Figure 1.1, except the boundaries between the various age groups are not shown
Source: Glymour, Pearl, and Jewell (2016)
Motivating Examples
Simpson’s paradox: does more exercise lead to higher cholesterol?
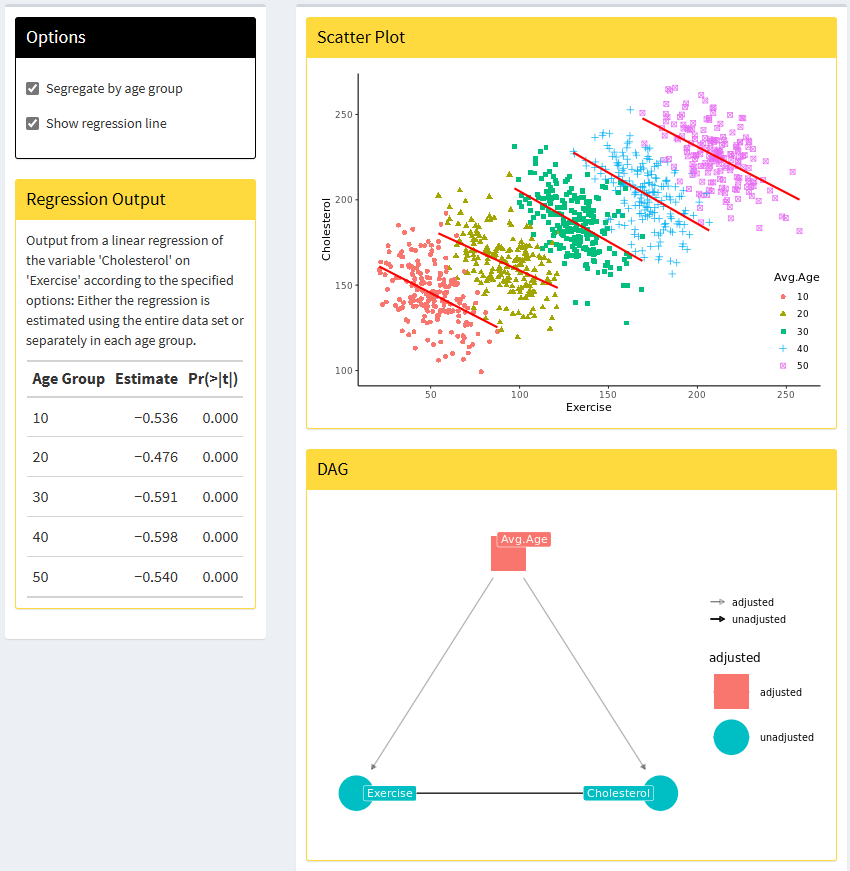
App: https://simpsons-paradox.herokuapp.com/
Source: Glymour, Pearl, and Jewell (2016)
Motivating Examples
Estimation of price elasticities
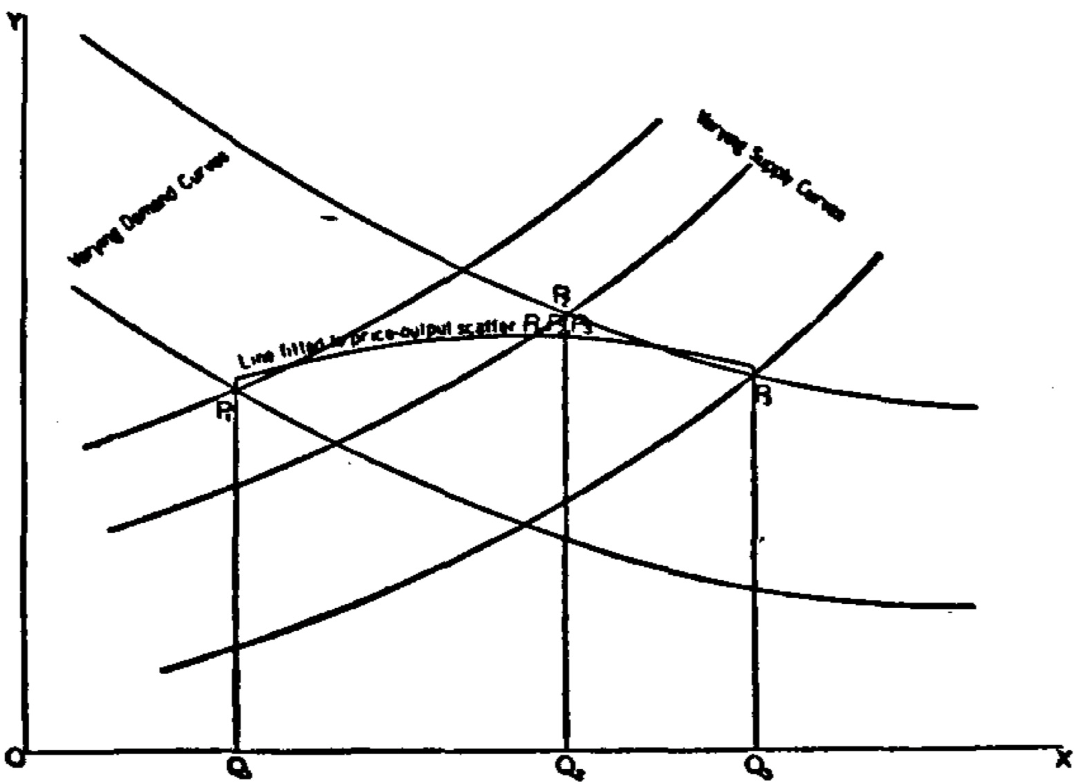
Figure 1.2: Wright’s graphical demonstration of the identification problem. Figure from Wright et al. (1928).
Motivating Examples
Labor market example
- What is the causal effect of a training on employees’ wages?
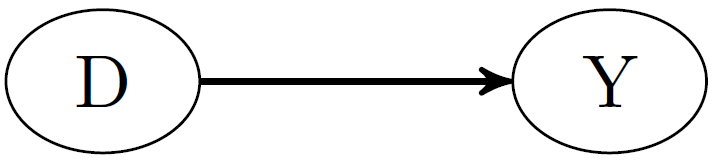
Figure 2.1.1: The causal effect of the treatment on the outcome
Source: Huber (2023), Chapter 2.1
Motivating Examples
Chocolate consumption and nobel prizes
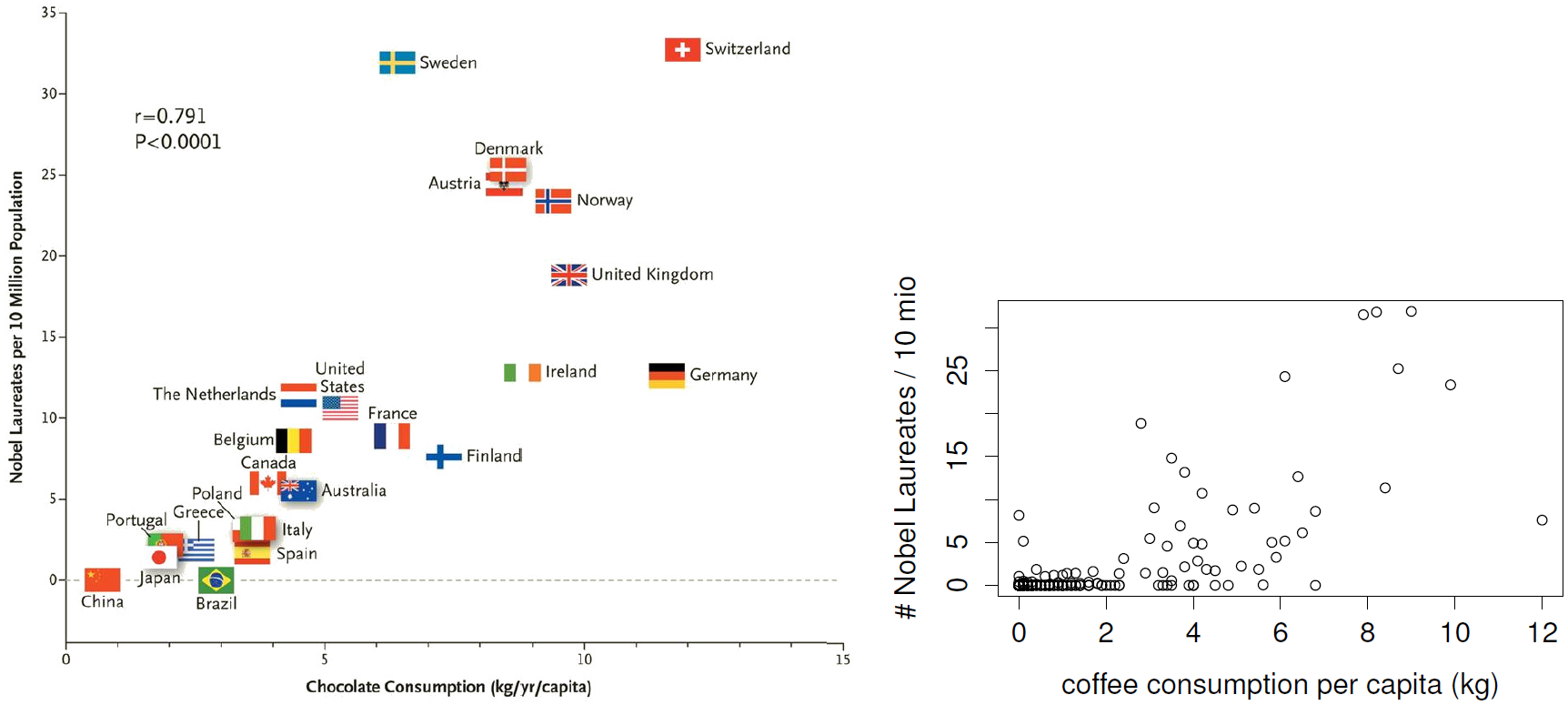
Figure 1.1: The left figure is slightly modified from Messerli (2012), it shows a significant correlation between a country’s consumption of chocolate and the number of Nobel prizes (averaged per person). The right figure shows a similar result for coffee consumption; the data are based on Wikipedia (2013b,a).
Source: Peters (2015)
Motivating Examples
Chocolate consumption and nobel prizes


Figure 1.2: Two online articles (downloaded from confectionarynews.com and forbes.com on Jan 29th 2013) drawing causal conclusions from the observed correlation between chocolate consumption and Nobel prizes, see Figure 1.1.
Source: Peters (2015)
Introduction to Causality
Map of causality
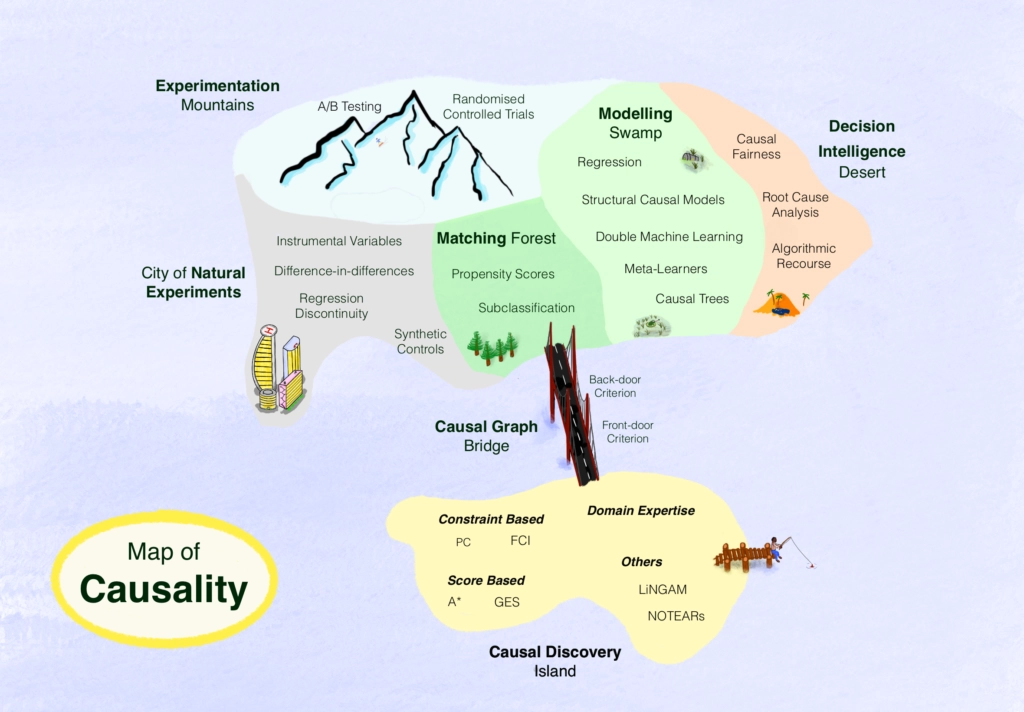
Source: “Map of Causality.” (2023)
Introduction to Causality
Directed acyclic graphs (DAGs)
Graphical methods to illustrate causal relationships
Graphs allow to make statements on statistical relationship of variables, e.g. stochastic independence
Two example DAGs
- RCT with \(D\rightarrow Y\) (see Huber (2023), Figure 2.1.1)
Figure 2.1.1: The causal effect of the treatment on the outcome
Introduction to Causality
Directed acyclic graphs (DAGs)
- Observational Study / Confounding: \(D \rightarrow Y\), \(D \leftarrow U \rightarrow Y\) (see Huber (2023), Figure 2.2.2)
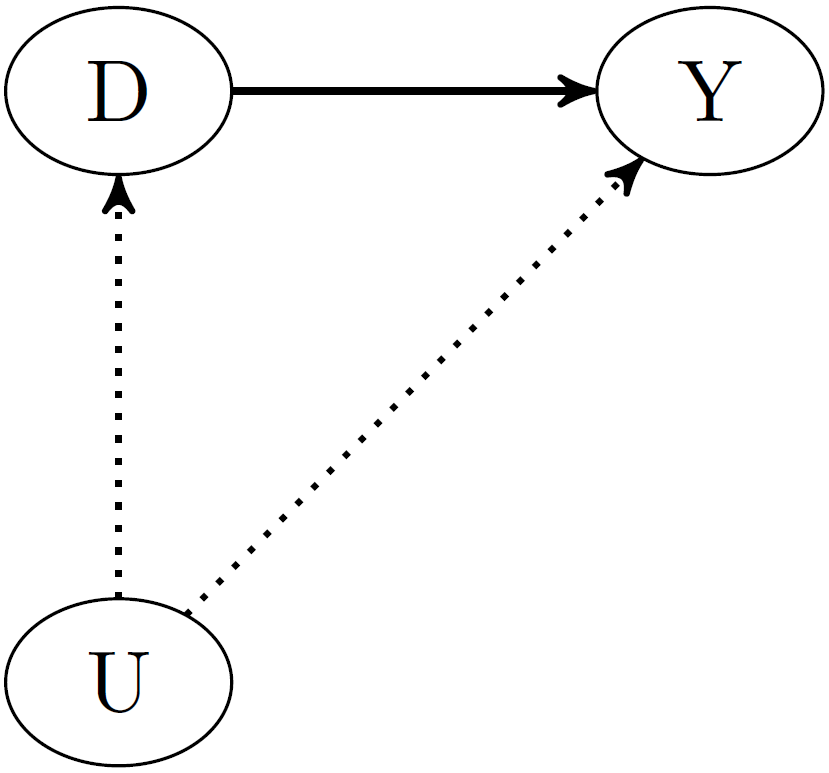
Figure 2.2.2: Treatment selection bias