Definition of Causal Effects
Causal Inference and Digital Causality Lab
University of Hamburg
Definition of Causal Effects
Example
Throughout this course, we will occasionally refer to a case study from the real-world (Source: zeit.de)

Source: zeit.de
Question: How would you define a causal effect in this setting?
Definition of Causal Effects
- For simplification, assume that
- we have a dichotomous (i.e., binary) treatment variable \(A\) (1: treated; 0: untreated) and
- a binary outcome \(Y\).
- We want to learn the causal effect of \(A\) on the outcome variable \(Y\). In our case study,
- \(A = 1\): Pollution is severe, i.e., it exceeds a certain threshold,
- \(A = 0\): Pollution is not severe, i.e., below a threshold,
- \(Y = 1\): A person dies,
- \(Y = 0\): A person survives.
Definition of Causal Effects
Definition
We define a causal effect for an individual as: Treatment \(A\) has a causal effect on \(Y\) if \[Y^{a=1} \neq Y^{a=0}.\]
Note that the definition is based on counterfactual outcomes \(Y^{a=0}, Y^{a=1}\).
Only one is factual, i.e., observable in reality.
Thus, individual effects cannot be identified, in general. This is sometimes called the fundamental problem of causal inference.
Definition of Causal Effects
- We will illustrate some of the ideas in a made-up data example on the causal effect of high pollution \(A\) on persons’ mortality \(Y\).
| i | Y^{a=0} | Y^{a=1} |
|---|---|---|
| 1 | 0 | 1 |
| 2 | 1 | 1 |
| 3 | 0 | 1 |
| 4 | 1 | 0 |
| 5 | 0 | 1 |
Definition of Causal Effects
- The fundamental problem of causal inference says that we will never observe counterfactual outcomes. For instance, we would observe the following table in reality, if treatment \(A\) was randomized.
| i | Y^{a=0} | Y^{a=1} | a |
|---|---|---|---|
| 1 | 0 | 0 | |
| 2 | 1 | 0 | |
| 3 | 1 | 1 | |
| 4 | 0 | 1 | |
| 5 | 0 | 0 |
Definition of Causal Effects
Definition
An average causal effect is present if \[P(Y^{a=1} = 1) \neq P(Y^{a=0} = 1),\]
or, more generally for nondichotomous outcomes \[E(Y^{a=1}) \neq E(Y^{a=0}).\]
Fine Points
Interference between Subjects
Present if outcome depends on other individuals’ treatment status \(\Rightarrow\) \(Y_i^{a}\) is not well defined.
SUTVA-Assumption maintained throughout this course: “Stable-Unit-Treatment-Value Assumption” (Rubin 1980)
Multiple Versions of Treatment
There could be different versions of a “treatment” \(\Rightarrow\) \(Y_i^{a}\) is not well defined.
Assumption of “treatment variation irrelevance” throughout this course.
Measures of Causal Effect
- Effect measures quantify the causal effect on different scales.
Representation of CAUSAL NULL HYPOTHESIS
\[\begin{align*} & P(Y^{a=1} = 1) - P(Y^{a=0} = 1) = 0 \quad \quad \text{ (Causal risk difference)} \\ \\ & \frac{P(Y^{a=1} = 1)}{P(Y^{a=0} = 1)} = 1 \quad \quad \quad \quad \quad \quad \quad \quad \quad \text{ (Causal risk ratio)} \\ \\ & \frac{ P(Y^{a=1} = 1) / P(Y^{a=1} = 0)}{ P(Y^{a=0} = 1) / P(Y^{a=0} = 0)} = 1 \quad \quad \quad \text{ (Causal odds ratio)} \end{align*}\]
Comment
- Usually, it depends on the question of interest whether the CRD, CRR or COR is used to quantify an causal effect.
Question: Can you interpret the different quantifications of the causal effect in the case study?
Inherent Problems in Causal Inference
What are problems inherent to causal inference?
- We already pointed at the fundamental problem of causal inference: We have to work with factuals since counterfactuals are not observable by definition.
- We observe \(Y = Y^{a=0} \cdot (a-1) + Y^{a=1} \cdot (a)\), only.
- Moreover, we do not observe the population, in general. We have to base our studies on random samples / random control trials (RCT).
Inherent Problems in Causal Inference
- For instance, in our made-up data example, we treated the observations in the table as they were a population of 5 persons. However, we usually work with (random) samples from the general population.
| i | Y^{a=0} | Y^{a=1} |
|---|---|---|
| 1 | 0 | 1 |
| 2 | 1 | 1 |
| 3 | 0 | 1 |
| 4 | 1 | 0 |
| 5 | 0 | 1 |
Inherent Problems in Causal Inference
Hence, even if we could observe counterfactual outcomes, we cannot simply read them off. We have to use statistical estimation.
Also, simple calculations of causal effects are not meaningful if we work with samples. We have to perform proper statistical tests to reject causal hypotheses.
Inherent Problems in Causal Inference
Further problems inherent to causal inference:
- Even worse, we cannot use data from randomized control studies in many cases.
\(\Rightarrow\) These problems are the reasons why we need a profound statistical knowledge to perform causal research in practice.
Random Variability
Samples - Two Sources of Random Error
- Sampling variability:
- We only dispose of \(\hat{P}(Y^{a=1} = 1)\) and \(\hat{P}(Y^{a=0} = 1)\).
- We need statistical procedures to test the causal null hypothesis.
- Nondeterministic counterfactuals:
- \(Y^{a=1}\) and \(Y^{a=0}\) may not be fixed but contain a stochastic component.
\(\Rightarrow\) We will talk about the statistical methods later. First, we need to get familiar with the conceptual basics.
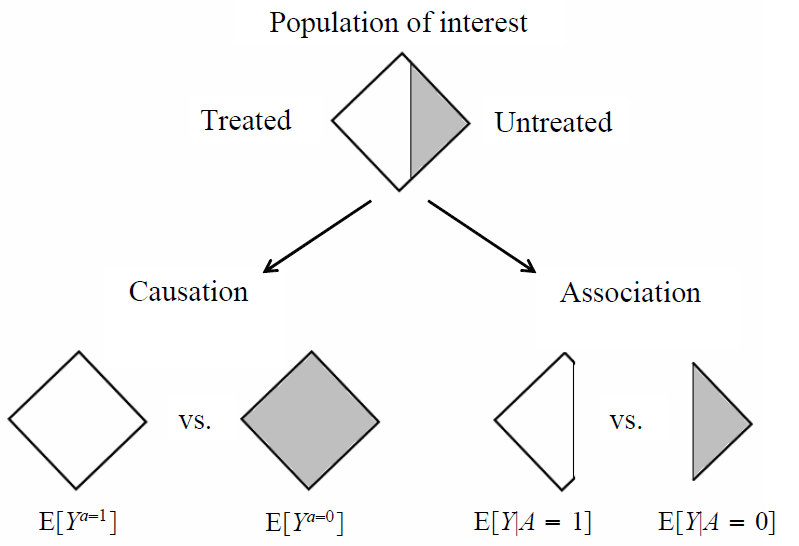
Causation vs. Association
Suppose, we observe the following data in our case study.
| i | Y | A |
|---|---|---|
| 1 | 0 | 0 |
| 2 | 1 | 0 |
| 3 | 1 | 1 |
| 4 | 0 | 1 |
| 5 | 0 | 0 |
The probability to die if treated is
\(P(Y=1|A=1)=\) 0.5.
Causation vs. Association
When \(P(Y=1|A=1)=P(Y=1|A=0)\), we say that \(Y\) and \(A\) are independent, i.e. \(Y \perp \!\!\! \perp A\), or equivalently, \(A \perp \!\!\! \perp Y\).
We say, that \(A\) and \(Y\) are dependent or associated when \(P(Y=1|A=1) \neq P(Y=1|A=0)\).
In our example, \(P(Y=1|A=0)=\) 0.3333 \(\Rightarrow\) \(A\) and \(Y\) are associated.
The associational risk difference (ARD), risk ratio (ARR), and odds ratio (AOR) quantify the strength of the association. These measures are subject to random variability!
Causation vs. Association
Association Measures
\[\begin{align*} & P(Y=1| A=1) - P(Y=1| A = 0) \text{ (Associational risk difference)} \\ \\ & \frac{P(Y=1| A=1)}{P(Y=1| A = 0)} \quad \quad \quad \quad \quad \quad \quad \quad \quad \text{ (Associational risk ratio)} \\ \\ & \frac{ P(Y=1| A=1) / P(Y=0| A = 1)}{ P(Y=1| A=0) / P(Y=0| A = 0)} \quad \quad \text{ (Associational odds ratio)} \end{align*}\]
- In our example, we have \(ARD=\) 0.1667 and \(ARR=\) 1.5.
Causation vs. Association
Mean independence
- For continuous \(Y\) we define mean independence between treatment and outcome as \[E(Y|A=1) = E(Y|A=0).\]
Probably the most Important Question
- If we consider the relationship of \(A\) and \(Y\), do we talk about causation or association?
Or, as stated in Hernán and Robins (2010, 12) :
“The question is then under which conditions real world data can be used for causal inference.”
Probably the most Important Question
References
References
Causal Inference & DCL