Mind the Trends: How to illustrate the common trend in a DiD-Design
Understanding Key Concepts in DiD Analysis
A DiD is a statistical technique used to estimate the causal effect of a treatment by comparing the differences in outcomes over time between a group that is exposed to the treatment and a group that is not. It helps to control for time-invariant unobserved heterogeneity. Here, a treatment group is exposed to the intervention or treatment.The group of subjects or entities that are not exposed to the intervention or treatment, serving as a baseline to compare the treatment group’s outcomes. In our case, some districts receive a minimum wage, while others are not.
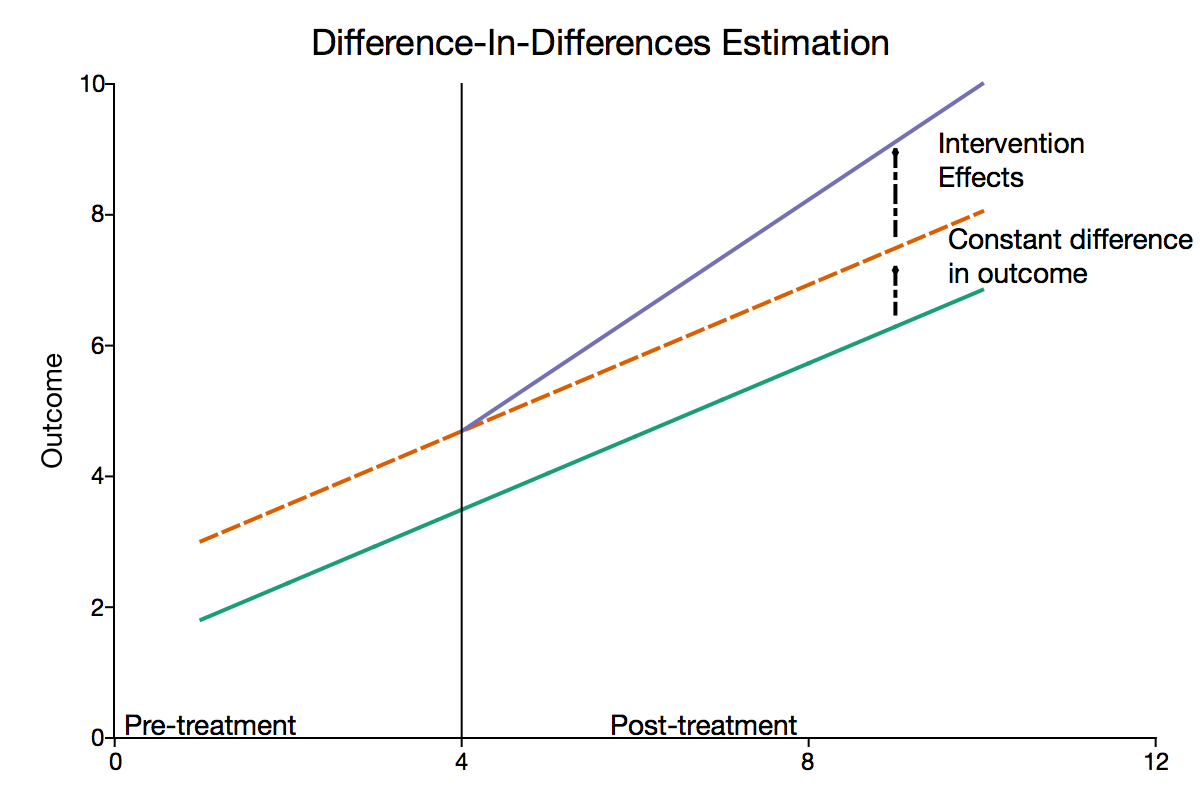
A DiD design has assumption that, in the absence of treatment, the treatment and control groups would have followed the same trend over time. This is also known as the parallel trend assumption.
Anything that derivatives from that assumed parallel trend is considered to be the treatment effect (D). This is the effect that we are going to calculate with our data set testdata. For this project, we want to highlight the effect of the common trend, meaning that even without intervention, the outcome in the treatment group is also rising (as indicated by the green line). Without accounting for the common trends, we end up overestimating the effects of our treatment and risking to infer wrong policy implications.
Now that we have the theoretical basis for a DiD-Design, lets get to the empirical part.
Install packages
Before we get started, we made sure to have all the necessary packages that help us to visualize the data.
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(gghighlight)
Warning: package 'gghighlight' was built under R version 4.4.1
library(rmarkdown)
Warning: package 'rmarkdown' was built under R version 4.4.1
Load data
To load the data from our generated data set, we first set the working directory and read in the excel file. Note that we saved our data in the csv format.
Lets first get a look at how our data is structured. If you open the testdata, you see that we have 338 observations (in our case city districts) and five variables. We observe the employment rate (employ) from these 338 districts over the years from 1979 to 1986. Fortunately, we also know whether the minimum - wagetreatment was (or will be) imposed in the districts. You can see this is the dummy variable wage. We also included the dummy variable year81, to make it possible to filter the years after the treatment was introduced to the districts in 1981. cbd shows the distance the districts have to the city center, which might be interesting if you would want to run a regression that accounts for geographical neighborhood.
When we plot a DiD, we first need to think about what we want to show. We have a treatment and a control group that we both observe before and after the treatment in 1981. This is why we first filtered the data into four groups using the dplyr package.
testdata <- testdata %>%mutate(group =case_when( wage ==0& year <1981~"wage_0_pre", wage ==0& year >=1981~"wage_0_post", wage ==1& year <1981~"wage_1_pre", wage ==1& year >=1981~"wage_1_post" ) )
Lets run code to illustrate the data in a plot!
testdata$wage =as.factor(testdata$wage)ggplot(data = testdata, aes(x = year, y = employ, color = wage)) +geom_point() +stat_summary(fun = mean, geom ="line", aes(group = wage), linetype ="solid") +geom_vline(xintercept =1981, color ="red", linetype ="dashed") +labs(x ="Year",y ="Employment in Percentage",color ="Group",title ="Impact of Minimum Wage Introduction on Employment",subtitle ="Difference-in-Differences Analysis" ) +scale_color_manual(values =c("red", "green"), labels =c("no min wage", "min wage")) +theme_minimal()
What we see in this figure is the change in the employment rates in the districts that do and do not receive the minimum wage treatment in 1981. Note that the employment rates before the introduction on treatment was similar in both groups of districts. This is what we meant by the parallel trend assumption. So it is quite clear, that minimum wage has a stark effect on the employment. But how big is the effect?
Naive estimation
The first intuition is to compare the employment rate after 1981 in the treatment group and the control group
#Here we show that the average employment after 1981 is approximately 77 percentmean_post_non_treatment <- testdata %>%filter(year >=1981& wage ==0) %>%summarize(mean_employ =mean(employ))print(mean_post_non_treatment)
mean_employ
1 40.10092
#Here we show that the average employment is approximately 40 percentprint(mean_post_treatment - mean_post_non_treatment)
mean_employ
1 37.25093
The calculation shows that after 1981, the treatment group has an average of 37 percentage points more employment than the control group. A policy implication would be to introduce minimum wage everywhere and to expect employment to rise by 37 percent. How great is that! But what is missing from this interpretation?
Estimation that accounts for business-cycles
We completly ignored the common trend and the unit specific effects until now. Well then lets look how the employment rate in non - treated control group changes over time. Therefore, we calculate the mean employment before and after 1981 and subtract these values from each other.
It seems like the employment in our control group changed a bit, even without state intervention. Keep in mind that the treatment group saw a rise in employment by 37 percentage points on average, so these 12 percentage points are quite impressive; due to the common trend of conjuncture, employment in the non-treated also rise. So is state intervention and minimum wage introduction useless? What is the real causal effect of minimum wage on the treated districts? We will find out by employing a DiD-Design.
DiD-Design
To get the real causal effect, we have to account for the two pitfalls of the naive estimation we did just above: the unit specific effects and the common trend. So first, we subtract the differences in treatment and control group before and after treatment; by doing this, we get rid of districts specific effects. After that, we we subtract these differences again before and after 1981. Here, we account for the common trend we just observed. Now you know where the design got its name from - these are a lot of differences. To make the following calculations easier, we call the first step D1. Here we take the differences of treatment and control group to even out the unit specific effects. In D2, we account for the common trend by subtracting the differences before and after 1981.
Lets start with D1. Here we still have to define the group mean_pre_treatment
Now we see that we had a difference in control and treatment group of 10 percent before the labor policy and of 37 percent after the labor policy without accounting for the rise in employment in the control group.
D2:
att <- diff_d1.2- diff_d1.1print(att)
mean_employ
1 27.00851
After taking the common trend of rising employment into account, the difference is 27 percentage points. Remember that we first estimated the effect of minimum wage to be 37 percent? The real causal effect of minimum wage is 10 percentage points lower after correcting for unit specific effects and conjuncture.
Now let´s get back to the theory and reconstruct what we actually did here.
Concept of a DiD calculation. MW = Minimum wage (district specific effects), NMW = No minimum wage, T = Time, D = Treatment
Districts
Period
Outcome Y
D1
(YPost - YPre)
D2
(D1MW - D1NMW)
Minimum wage
Pre
Y = MW
Post
Y = MW + T + D
(MW + T +D) - MW = T+D
(T+ D) - T = D
No minimum wage
Pre
Y = NMW
Post
Y = NMW + T
(NMW + T) - NMW = T
In D1, we subtract the the Outcome Y from the pre-treatment period from the Y in the post-treatment period for our treated districts. In the post treatment period, the outcome in the treated districts are compound of the districts specific effects, the time effect (T) and the effect of the minimum wage (D). When we subtract the district specific effects from the pre-treatment period, we are left with only the time and treatment effect (T+D) for our treated districts. We do the same with the non-treated districts. Note that we don´t have a treatment effect (D) in these districts but only a time effect (T), because they did not got any labor market intervention. Here we are left with only the time effect in D1 for the nmw.
In D2, we are taking the difference of the differences in D1, meaning that we subtract the time effect T of the non-treated districts from the time and treatment effect (T + D) of the districts with minimum wage. This is what we did in order to account for the common trend of conjunction. This leaves us with only the pure effect of the minimum wage treatment D.
Limitations
A DiD-Design is a powerful tool to calculate the causal effects, however implementing a DiD holds some challenges. For the parallel trend assumption to hold, researchers have to find treatment and control groups that follow similar trends over time. Another difficulty lies in accounting for non-random assignment to treatment groups. And generalizing the findings to broader populations may be limited, effecting the external validity of the results.