# Simulierte Datenset.seed(123)n <-1000age <-rnorm(n, 30, 10)education <-rnorm(n, 12, 2)income <-5000+500* age +1000* education +rnorm(n, 0, 1000)# Treatment-Indikator (Teilnahme am Programm)treatment <-rbinom(n, 1, plogis(0.3* age -0.5* education))# Einkommen nach Behandlungincome_post <- income + treatment * (500+ (100* age)) +rnorm(n, 0, 1000)# Dataframe erstellendata <-data.frame(age, education, treatment, income_post)# 1. Matching anhand der Kovariaten durchführen, wobei der Propensity Score intern berechnet wirdmatch_it <-matchit(treatment ~ age + education, method ="nearest", data = data, caliper =0.1)
Warning: Fewer control units than treated units; not all treated units will get
a match.
# 2. Gematchte Daten extrahierenmatched_data <-match.data(match_it)# 3. Überprüfen der Balance der Kovariatenprint(summary(match_it))
Call:
matchit(formula = treatment ~ age + education, data = data, method = "nearest",
caliper = 0.1)
Summary of Balance for All Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean
distance 0.9063 0.3869 3.1782 0.3003 0.4320
age 32.9607 18.6048 1.6979 1.6467 0.4140
education 11.9552 12.6203 -0.3352 0.9106 0.0869
eCDF Max
distance 0.7163
age 0.6822
education 0.1407
Summary of Balance for Matched Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean
distance 0.6104 0.5947 0.0958 1.0773 0.0378
age 24.4119 22.3733 0.2411 3.0428 0.0544
education 12.4633 12.3546 0.0548 0.9319 0.0281
eCDF Max Std. Pair Dist.
distance 0.07 0.0986
age 0.11 0.5438
education 0.08 1.0853
Sample Sizes:
Control Treated
All 195 805
Matched 100 100
Unmatched 95 705
Discarded 0 0
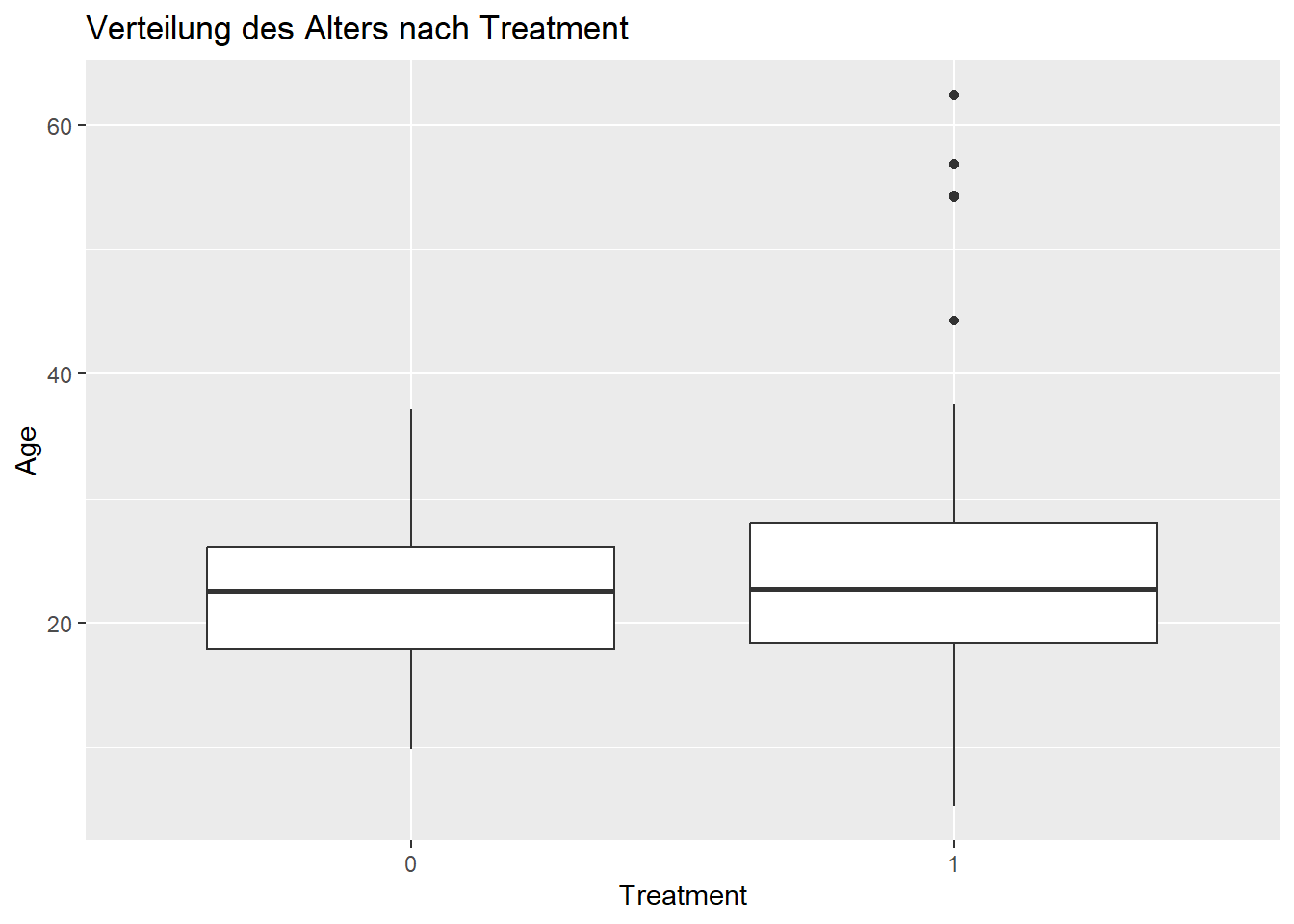
# 4. Visualisierung der Balance der Kovariaten nach Matchinglibrary(ggplot2)ggplot(matched_data, aes(x =factor(treatment), y = age)) +geom_boxplot() +labs(title ="Verteilung des Alters nach Treatment", x ="Treatment", y ="Age")
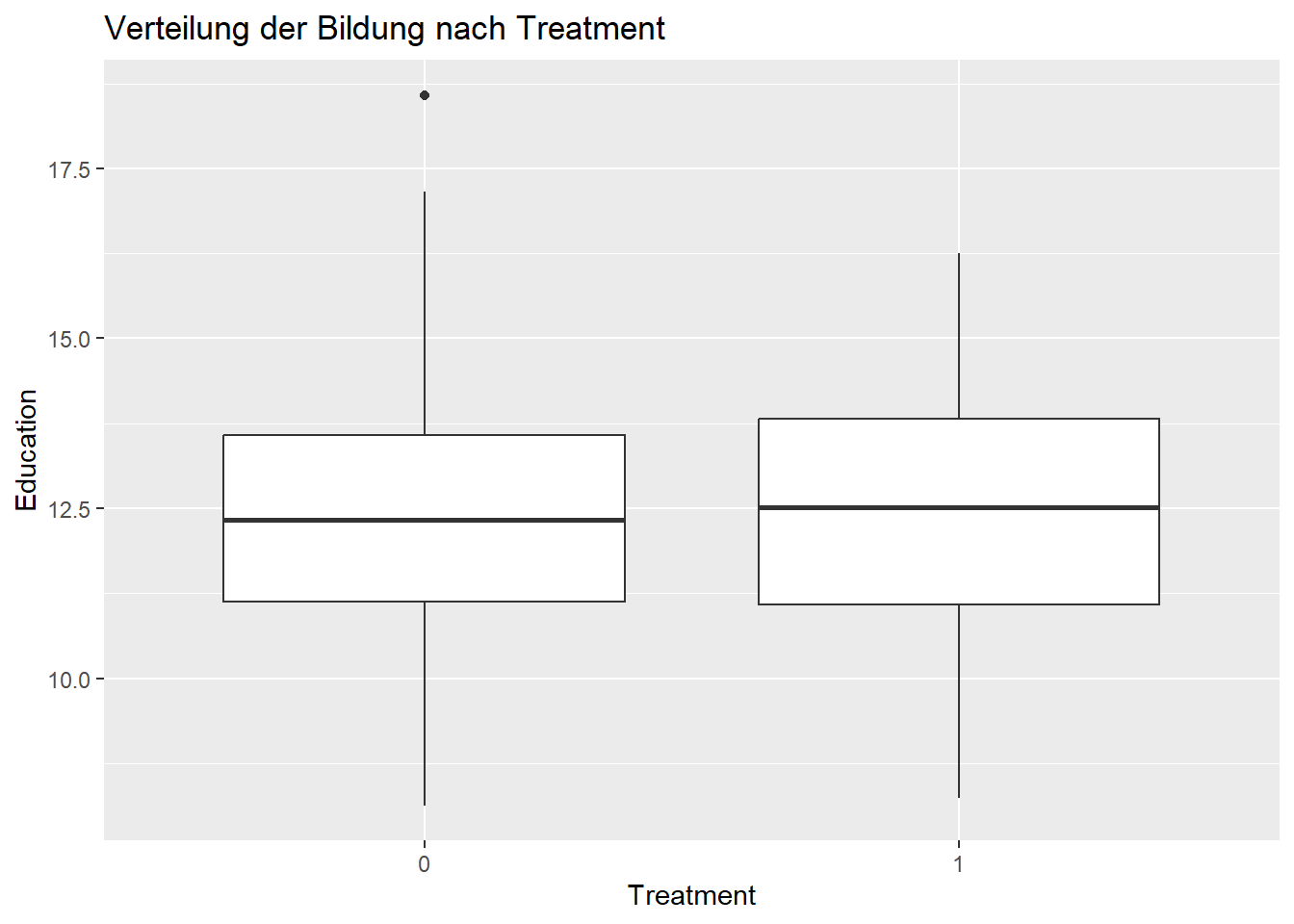
ggplot(matched_data, aes(x =factor(treatment), y = education)) +geom_boxplot() +labs(title ="Verteilung der Bildung nach Treatment", x ="Treatment", y ="Education")
# 5. Schätzen des Behandlungseffektsate_model <-lm(income_post ~ treatment, data = matched_data)summary(ate_model)
Call:
lm(formula = income_post ~ treatment, data = matched_data)
Residuals:
Min 1Q Median 3Q Max
-13335.2 -3180.6 -293.4 3351.1 22094.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 28552.1 545.5 52.343 < 2e-16 ***
treatment 4210.3 771.4 5.458 1.43e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5455 on 198 degrees of freedom
Multiple R-squared: 0.1308, Adjusted R-squared: 0.1264
F-statistic: 29.79 on 1 and 198 DF, p-value: 1.432e-07